同一批代理在跑两件事:
—— 前台账号要正常登录、发帖、改资料;
—— 后台爬虫要拉价格、抓评论、刷列表。
一开始大家图省事:
“反正都有代理,就放在一个池里轮着用。”
结果很快翻车:
- 采集一加速,前台账号就开始验证码、软封、限流;
- 某几条 IP 被爬虫打到 429,顺带把正在登录的账号一起拖下水;
- 你只看到“这个出口最近不太行”,却搞不清到底是谁干的。
问题不是“这家代理不行”,而是 业务流量和爬虫流量没有分工,在平台眼里混成了一团异常行为。
这篇就回答一个具体问题:
在同一套代理池下,业务流量与爬虫任务怎么拆开,才不会互相拖累?
一、先看清现状:所有流量都在一锅乱炖
现实里常见的混用方式是:
- 账号登录 / 操作,用的是同一个出口池;
- 爬虫抓页面 / 列表 / 报表,也用的是同一个出口池;
- “轮换策略”只关心 IP 使用次数,不管是账号请求还是爬虫请求。
平台日志看到的是:
- 同一 IP 上,一会儿是正常浏览、下单,一会儿是一秒几十个列表请求;
- 某个账号刚登录,接着就从同 IP 对全站商品疯狂遍历;
- 很多 IP 在同一时间段,对同类接口持续高频访问。
于是:
- 风控一刀下去,这个 IP 下所有会话都被提高检查等级;
- 正常账号的登录 / 操作成本被采集的“噪音”抬高;
- 你会误以为“账号本身有问题”,其实是被爬虫连坐。
底层原因就一句话:
平台只能以 IP + 行为整体判断风险,没法替你区分‘这是业务请求’还是‘这是爬虫请求’。
二、要拆分的不是“代理品牌”,而是“流量角色”
“同一套代理池”并不等于“一定要混着用”。
真正要拆的是三层角色:
- 账号身份流量
- 注册、登录、改资料、绑卡、申诉;
- 强绑定某个账号“是谁”。
- 业务功能流量
- 发帖、改价、改库存、调预算、看后台页面;
- 是账号在正常完成工作。
- 数据采集流量
- 刷全站商品、拉评论、跑价监、拉大报表;
- 不直接属于某个账号,而是你这边的“内部需求”。
如果三类流量从平台视角看 全都混在同一批 IP 上,风控很难不把你整体算成“风险高用户群”。
所以设计思路要变成:
在同一套代理资源内,刻意划出不同“出口角色”,每种角色只干一类活。
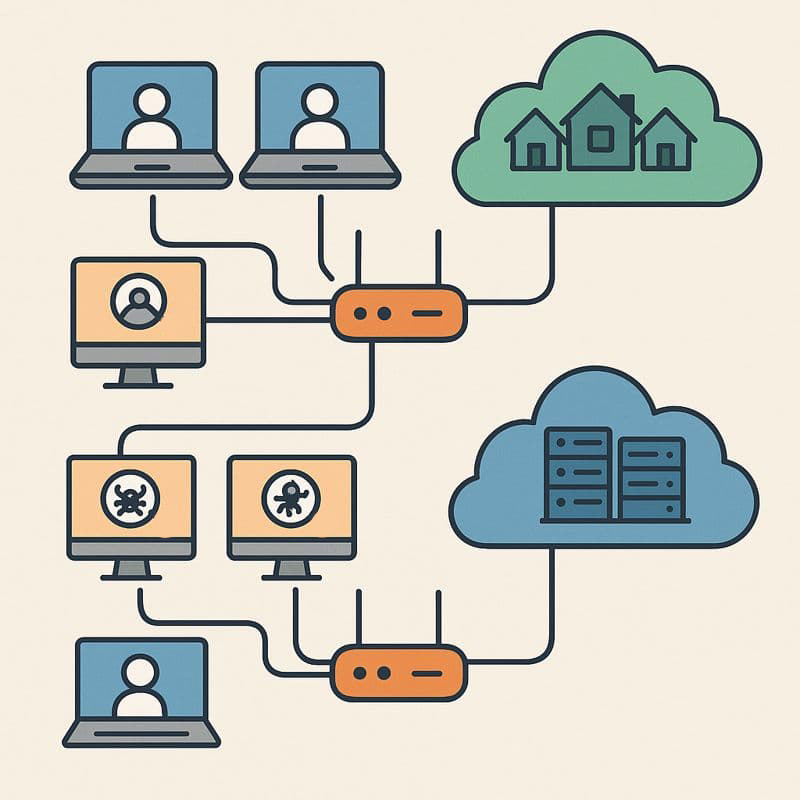
三、分工主线:账号吃“干净流量”,爬虫吃“有边界的脏活”
可以按这条主线来设计:
1. 身份 & 业务流量:只走“干净口”
这里包括:
- 登录、登出;
- 改个人信息 / 店铺信息 / 支付信息;
- 后台常规操作(发帖、改价、小规模查数据)。
规则:
- 选出一批“干净且稳定”的出口(住宅 / 稳定机房均可),标记为 BUSINESS_POOL;
- 每个账号绑定 1 条主出口 + 1 条备出口,固定国家 / 区域,不随意乱跳;
- 所有需要“看起来像真人”的请求,只走 BUSINESS_POOL。
注意:
- BUSINESS_POOL 不承载大规模遍历、扫站业务;
- 一旦发现某个出口因为别的原因被打出风控,短期内从 BUSINESS_POOL 下线,避免影响更多账号。
2. 采集流量:独立“干脏活”的出口
这里包括:
- 拿全量列表;
- 批量抓商品 / 评论 / 店铺信息;
- 频繁刷接口做监控。
规则:
- 从同一代理服务里,划一组专用出口,标记为 SPIDER_POOL;
- 所有爬虫请求只走 SPIDER_POOL,不准占用 BUSINESS_POOL;
- SPIDER_POOL 内允许更激进的轮换策略、更高的并发、更严厉的降速与封禁处理。
注意:
- 不在 SPIDER_POOL 上做登录、改资料、支付这类敏感操作,以免“脏口”和账号绑定;
- SPIDER_POOL 被限频了,就实话实说:该降速就降速,该加机器就加机器,不要偷偷把压力塞回 BUSINESS_POOL。
四、轮换与限速:靠“边界”而不是靠运气
哪怕出口已经分池,如果轮换和限速没逻辑,还是会互相拖累。
1. BUSINESS_POOL:以账号为单位控制节奏
- 每个账号会话(登录 → 一系列操作 → 结束)内,尽量固定一条出口;
- 账号之间可以共享出口,但同一时间一条出口上跑的账号数要有限制(新手可以先按 1 IP 对 3–5 个账号控制);
- 登录失败、验证码等情况出现后,不要立刻换出口连撞 5 次,而是延迟重试 + 降低当日操作频次。
这样做的目的很简单:
让平台相信——“这个账号就是从这里比较稳定地上来工作”。
2. SPIDER_POOL:以“任务批次”为单位轮换
- 把爬虫任务拆成小批次,比如每批 500–1000 个 URL;
- 每个批次固定使用一条出口,跑完再切下一条;
- 给每条出口设置 QPS 上限和最大并发连接数,超限就排队或暂停;
- 一旦检测到某条出口错误率长期偏高,就把它从 SPIDER_POOL 下线,避免持续撞墙。
这样,平台看到的是:
- 有一批“忙碌但相对平稳”的机器用户在浏览(BUSINESS_POOL);
- 还有一批“频率高、路径明显像脚本”的流量(SPIDER_POOL),即使被识别为采集,也不会连坐账号层。
在落地这些规则时,用易路代理会省不少心:你可以直接在后台把 BUSINESS_POOL 和 SPIDER_POOL 拆成两套线路组,住宅线集中给账号池用,机房线集中给爬虫池用,再给每个组单独设置并发和限速策略。脚本侧只认“业务池标签”和“采集池标签”,不关心具体 IP,后面要增减节点、切主备、淘汰问题线路,都可以在易路面板里完成,多账号和采集自然就跑在一套更干净、更可控的出口结构上。
五、新手可抄的最小方案:10 个账号 + 一个爬虫脚本
假设你的条件是:
- 有 10 个账号,需要每天登录、发几个内容、改一点价格;
- 有一个爬虫脚本,每天要抓 3000 个商品页;
- 手里是一整段共 20 条代理线路(不区分类型)。
可以按下面步骤改造:
步骤 1:人为切两池
- 从 20 条线路里挑出延迟稳定、错误少的 8 条,命名为 BUSINESS_POOL;
- 剩下 12 条命名为 SPIDER_POOL。
步骤 2:绑定账号
- 10 个账号,每 2 个账号绑定 BUSINESS_POOL 里的 1 条主出口 + 1 条备出口;
- 这 10 个账号的所有登录和后台操作,只能用 BUSINESS_POOL 的出口。
步骤 3:调整爬虫
- 3000 个商品拆成 6 个批次,每批 500 个;
- 每个批次按顺序使用 SPIDER_POOL 中的一条出口;
- 发现某批次错误率特别高,就标记对应出口为“冷却”,下两轮不再分配任务。
做到这一步,即使你的代理服务、节点本身完全没变,也会明显感到:
- 采集任务的异常不会立刻拖垮所有账号;
- 账号的验证码 / 掉线概率下降;
- 出现问题时可以快速定位是 BUSINESS_POOL 还是 SPIDER_POOL 在出事,而不是一头雾水。
六、别再让“一个大池子”毁掉所有努力
最后压缩成三点:
- 同一套代理资源,可以也应该在逻辑上分成不同“出口角色”。
- 账号相关的身份与业务流量,永远优先走“干净且节奏保守”的池。
- 爬虫相关的高频流量,集中在独立池里,用轮换和限速消化风险。
只要记住一句话:
“账号吃干净饭,爬虫吃隔离饭。”
你就能在不换代理、不额外花大钱的前提下,把现有代理用出更稳定的业务效果。